Bayesian optimization (BayesOpt) is an effective tool extensively utilized for international optimization jobs, such as hyperparameter tuning, protein engineering, artificial chemistry, robotic knowing, and even baking cookies BayesOpt is a fantastic method for these issues since they all include enhancing black-box functions that are pricey to examine. A black-box function’s underlying mapping from inputs (setups of the important things we wish to enhance) to outputs (a step of efficiency) is unidentified. Nevertheless, we can try to comprehend its internal functions by examining the function for various mixes of inputs. Since each examination can be computationally pricey, we require to discover the very best inputs in as couple of assessments as possible. BayesOpt works by consistently building a surrogate design of the black-box function and tactically examining the function at the most appealing or helpful input area, provided the info observed up until now.
Gaussian procedures are popular surrogate designs for BayesOpt since they are simple to utilize, can be upgraded with brand-new information, and supply a self-confidence level about each of their forecasts. The Gaussian procedure design constructs a possibility circulation over possible functions. This circulation is defined by a mean function (what these possible functions appear like usually) and a kernel function (just how much these functions can differ throughout inputs). The efficiency of BayesOpt depends upon whether the self-confidence periods forecasted by the surrogate design include the black-box function. Typically, specialists utilize domain understanding to quantitatively specify the mean and kernel criteria (e.g., the variety or smoothness of the black-box function) to reveal their expectations about what the black-box function must appear like. Nevertheless, for numerous real-world applications like hyperparameter tuning, it is extremely hard to comprehend the landscapes of the tuning goals. Even for specialists with appropriate experience, it can be challenging to limit proper design criteria.
In “ Pre-trained Gaussian procedures for Bayesian optimization“, we think about the obstacle of hyperparameter optimization for deep neural networks utilizing BayesOpt. We propose Active BayesOpt (HyperBO), an extremely adjustable user interface with an algorithm that gets rid of the requirement for measuring design criteria for Gaussian procedures in BayesOpt. For brand-new optimization issues, specialists can merely choose previous jobs that relate to the present job they are attempting to fix. HyperBO pre-trains a Gaussian procedure design on information from those picked jobs, and instantly specifies the design criteria prior to running BayesOpt. HyperBO takes pleasure in theoretical warranties on the positioning in between the pre-trained design and the ground fact, in addition to the quality of its options for black-box optimization. We share strong outcomes of HyperBO both on our brand-new tuning standards for near– advanced deep knowing designs and timeless multi-task black-box optimization standards ( HPO-B). We likewise show that HyperBO is robust to the choice of appropriate jobs and has low requirements on the quantity of information and jobs for pre-training.
 |
| In the standard BayesOpt user interface, specialists require to thoroughly choose the mean and kernel criteria for a Gaussian procedure design. HyperBO changes this manual spec with a choice of associated jobs, making Bayesian optimization simpler to utilize. The picked jobs are utilized for pre-training, where we enhance a Gaussian procedure such that it can slowly produce functions that resemble the functions representing those picked jobs. The resemblance manifests in specific function worths and variations of function worths throughout the inputs. |
Loss functions for pre-training
We pre-train a Gaussian procedure design by decreasing the Kullback– Leibler divergence (a typically utilized divergence) in between the ground fact design and the pre-trained design. Given that the ground fact design is unidentified, we can not straight calculate this loss function. To fix for this, we present 2 data-driven approximations: (1) Empirical Kullback– Leibler divergence (EKL), which is the divergence in between an empirical quote of the ground fact design and the pre-trained design; (2) Unfavorable log possibility (NLL), which is the the amount of unfavorable log probabilities of the pre-trained design for all training functions. The computational expense of EKL or NLL scales linearly with the variety of training functions. Additionally, stochastic gradient— based techniques like Adam can be utilized to enhance the loss functions, which even more reduces the expense of calculation. In well-controlled environments, enhancing EKL and NLL cause the exact same outcome, however their optimization landscapes can be extremely various. For instance, in the most basic case where the function just has one possible input, its Gaussian procedure design ends up being a Gaussian circulation, explained by the mean ( m) and variation ( s). For this reason the loss function just has those 2 criteria, m and s, and we can envision EKL and NLL as follows:.
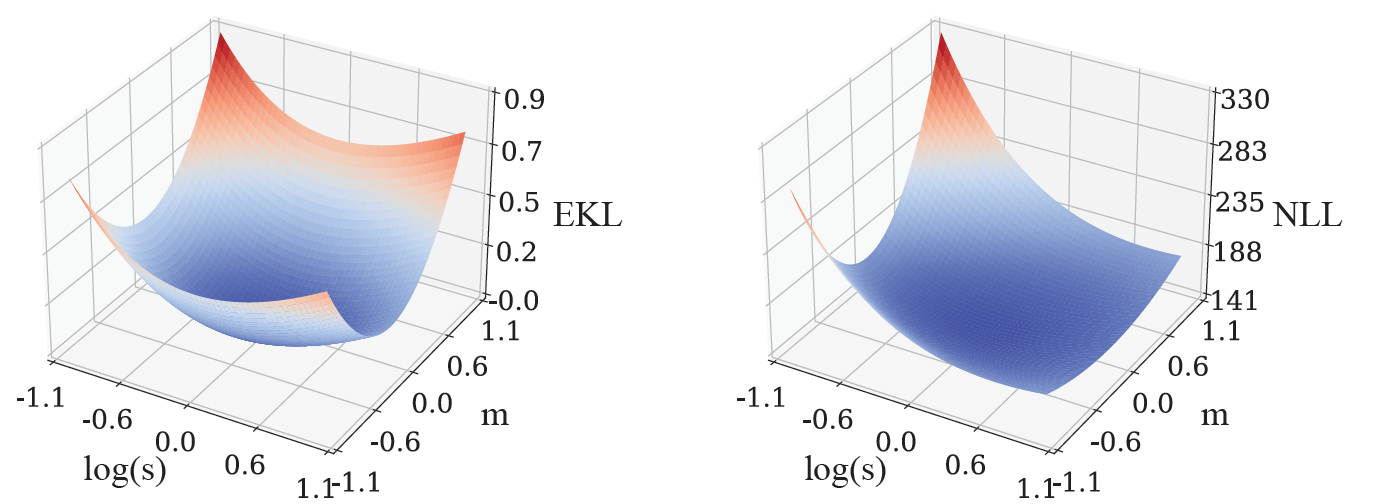 |
| We replicate the loss landscapes of EKL ( left) and NLL ( right) for a basic design with criteria m and s The colors represent a heatmap of the EKL or NLL worths, where red represents greater worths and blue represents lower worths. These 2 loss landscapes are extremely various, however they both goal to match the pre-trained design with the ground fact design. |
Pre-training enhances Bayesian optimization
In the BayesOpt algorithm, choices on where to examine the black-box function are made iteratively. The choice requirements are based upon the self-confidence levels supplied by the Gaussian procedure, which are upgraded in each version by conditioning on previous information points obtained by BayesOpt. Intuitively, the upgraded self-confidence levels must be ideal: not extremely positive or too uncertain, considering that in either of these 2 cases, BayesOpt can not decide that can match what a specialist would do.
In HyperBO, we change the hand-specified design in standard BayesOpt with the pre-trained Gaussian procedure. Under moderate conditions and with sufficient training functions, we can mathematically validate great theoretical homes of HyperBO: (1) Positioning: the pre-trained Gaussian procedure warranties to be close to the ground fact design when both are conditioned on observed information points; (2) Optimality: HyperBO warranties to discover a near-optimal service to the black-box optimization issue for any functions dispersed according to the unidentified ground fact Gaussian procedure.
 |
| We envision the Gaussian procedure (locations shaded in purple are 95% and 99% self-confidence periods) conditional on observations (black dots) from an unidentified test function (orange line). Compared to the standard BayesOpt without pre-training, the forecasted self-confidence levels in HyperBO records the unidentified test function better, which is a crucial requirement for Bayesian optimization. |
Empirically, to specify the structure of pre-trained Gaussian procedures, we select to utilize extremely meaningful mean functions designed by neural networks, and use distinct kernel functions on inputs encoded to a greater dimensional area with neural networks.
To examine HyperBO on difficult and sensible black-box optimization issues, we produced the PD1 standard, which consists of a dataset for multi-task hyperparameter optimization for deep neural networks. PD1 was established by training 10s of countless setups of near– advanced deep knowing designs on popular image and text datasets, in addition to a protein series dataset. PD1 consists of around 50,000 hyperparameter assessments from 24 various jobs (e.g., tuning Wide ResNet on CIFAR100) with approximately 12,000 maker days of calculation.
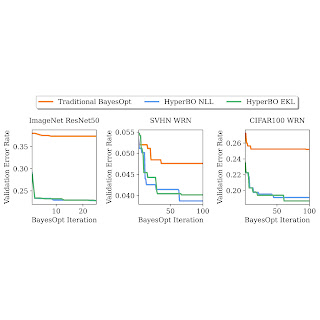
We show that when pre-training for just a couple of hours on a single CPU, HyperBO can considerably exceed BayesOpt with thoroughly hand-tuned designs on hidden difficult jobs, consisting of tuning ResNet50 on ImageNet Even with just ~ 100 information points per training function, HyperBO can carry out competitively versus standards.
 |
| Tuning recognition mistake rates of ResNet50 on ImageNet and Wide ResNet (WRN) on the Street View Home Numbers (SVHN) dataset and CIFAR100. By pre-training on only ~ 20 jobs and ~ 100 information points per job, HyperBO can considerably exceed standard BayesOpt (with a thoroughly hand-tuned Gaussian procedure) on formerly hidden jobs. |
Conclusion and future work
HyperBO is a structure that pre-trains a Gaussian procedure and consequently carries out Bayesian optimization with a pre-trained design. With HyperBO, we no longer need to hand-specify the specific quantitative criteria in a Gaussian procedure. Rather, we just require to determine associated jobs and their matching information for pre-training. This makes BayesOpt both more available and more reliable. An essential future instructions is to make it possible for HyperBO to generalize over heterogeneous search areas, for which we are establishing brand-new algorithms by pre-training a hierarchical probabilistic design
Recognitions
The following members of the Google Research study Brain Group performed this research study: Zi Wang, George E. Dahl, Kevin Swersky, Chansoo Lee, Zachary Nado, Justin Gilmer, Jasper Snoek, and Zoubin Ghahramani. We want to thank Zelda Mariet and Matthias Feurer for aid and assessment on transfer knowing standards. We ‘d likewise like to thank Rif A. Saurous for useful feedback, and Rodolphe Jenatton and David Belanger for feedback on previous variations of the manuscript. In addition, we thank Sharat Chikkerur, Ben Adlam, Balaji Lakshminarayanan, Fei Sha and Eytan Bakshy for remarks, and Setareh Ariafar and Alexander Terenin for discussions on animation. Lastly, we thank Tom Small for developing the animation for this post.